Data flow analysis: DepGraph
Overview:
This article deals with the dataflow analysis in binary programs. There are many algorithms and articles about this vast subject, so we will only cover a sample of them, highlight their advantages and drawbacks, then we will introduce the DepGraph (for dependency graph) algorithm implemented in Miasm.
This analysis is based on Miasm revision 6fef06f. The corresponding Elfesteem revision is 1ee9171.
Some details on the implementation/examples can be found in the article/slides/video published in the SSTIC conference: Graphes de dépendances : Petit Poucet style (WARNING: French material!).
Problem
In binary analysis, a recurrent problem is to track back a register or memory value (we will call them variables in the rest of the blog entry).
To present the problem, we will use a simplified representation instead of barbarous assembly. Here is a first example:

Basic flow graph example
Here are some questions which can be asked when reversing such a program:
- Which lines are involved in the computation of the final value of a?
- What are the possible values of a?
Use-Def
The Use-Def algorithm returns, for a given use of a variable X, all the definitions of this variable X that can reach that use without any other intervening definitions. This is very useful to extract only the lines which have an impact on a desired variable. But those properties are computed independently of the path taken during the execution, which means that the resulting analysis is the union of all potential paths. Here is an example:

Basic if/then/else example
The result of the use-def algorithm for this example is the following:

Use-def result
The solution shows that both branches are important, but you cannot retrieve the different values of a and b directly from this result ((2, 2) and (3, 1)).
Path-sensitive
To get those values, you can use a path-sensitive algorithm. Such an algorithm will generate all possible paths which reach the desired definition of a. The advantage is that you will effectively get the right values. But this analysis is known to explode combinatorially in presence of multiple branch and loops.

Example with a loop
In this example, the path sensitive algorithm will return 3, 5, 7, 9, … Dealing with this problem is an active research area, and is outside the scope of this post.
Other
Many other algorithms exist (Tainting, Slicing, …) but they are either too restrictive (cannot have different solutions in simple if/then/else cases) or too exhaustive (explosion in nested loops).
DepGraph
The Dependency Graph is an algorithm somewhere between path-sensitive and path-insensitive. The goal is to have the distinguishable values whenever it’s possible, and to return the different paths containing loops in relevant cases.
The main idea is to back track values in every path which only generates new variable dependencies.
In the first example, the algorithm will return only one solution:
a_lbl2 <- b_lbl1
b_lbl1 <- c_lbl0
c_lbl0 <- 0x0
In the if/then/else example, the algorithm will consider taking both branches independently. Since each branch generates a different variable dependency set, two solutions are returned:
First solution:
a_lbl3 <- b_lbl1, c_lbl0
b_lbl1 <- 0x2
c_lbl0 <- 0x1
Second solution:
a_lbl3 <- b_lbl2, c_lbl0
b_lbl1 <- 0x3
c_lbl0 <- 0x1
Note those solutions do not include any loop, so we can compute the value of a in each case.
In the loop example, things are getting complicated. Let’s run the algorithm. We are tracking a in the block lbl2. It depends on b, so we are now tracking b. lbl2 has only one parent, lbl1, so we are now tracking b in lbl1, in which it’s modified, b_lbl1. As the equation is b = b+1, we are still tracking b in the parents of lbl1. In this case, lbl1 has two parents: lbl0 and lbl1, so we will split the analysis here.
Let’s consider lbl0 first. b is written by a constant, so no more variables are tracked, and we have our first solution (without any loop).
First solution:
a_lbl2 <- b_lbl1
b_lbl1 <- b_lbl0, 0x2
b_lbl0 <- 0x1
The second solution considers lbl1 as parent. b_lbl1 now depends on itself, and we are still tracking b. As we created a new dependency (b_lbl1 depends on b_lbl1) and lbl1 has two parents, we will split the analysis again. We have reached the same point than before, but with a different state.
Let’s take lbl0 as parent. b is written with a constant, so no more variables are tracked, and we have our first solution (involving a loop).
Second solution:
a_lbl2 <- b_lbl1
b_lbl1 <- b_lbl1, 0x2
b_lbl1 <- b_lbl0, 0x2
b_lbl0 <- 0x1
The remaining analysis needs to loop again in the lbl1 block. The variable b depends on b_lbl1, and we reached the top of the block lbl1 to propagate the analysis in every parent.
But hey! This state has already been reached and did not add any new variables dependencies in its analysis. This state has already been handled and can be dropped. As no more analyses are queued, the algorithm ends.
In the end, we then have two solutions:
- one without any loop (we execute lbl1 exactly once), in which we can compute the value of a (3)
- another one, which can execute the block lbl1 two or more times (in which we cannot give all the solutions)
Let’s take another example to analyze the algorithm’s output.

Example including a loop with no impact on b
Guess what? The algorithm returns only one solution:
Solution:
a_lbl2 <- b_lbl0
b_lbl0 <- 0x1
The trick is when we backtrack b in the parents of the block lbl1, if the analysis back tracks in the lbl1 parent, the block will not add any new variables dependencies, compared to the solution which directly backtracks from the block lbl0, so this branch’s analysis is dropped.
You can argue that the program may crash before reaching the assignment or, that the loop may never end, so a will never be assigned to. Haha! You are right. But let’s say that the termination analysis is a bit too complex for us, so that we always assume that we run the analysis in reachable nodes. And under this condition, at the block lbl2, a will have the correct computed value!
Last but not least, you can track multiple variables in the same analysis (from the same starting point): the algorithm will proceed by computing the possible values of the group made by those variables (it won’t return independent solutions for each variable). Here is an example:
Multi tracking
If you want information on the call arguments, you will run the algorithm from lbl3 on the variables (a, b). The algorithm will return two solutions:
First solution:
a_lbl3 <- a_lbl1
a_lbl1 <- 0x2
b_lbl3 <- b_lbl1
b_lbl1 <- 0x2
Second solution:
a_lbl3 <- a_lbl2
a_lbl2 <- 0x3
b_lbl3 <- b_lbl2
b_lbl2 <- 0x1
Those solutions have no loops, so their values can be computed. In this case: (2, 2) and (3, 1). This is more precise than running the algorithm on a, which gives you two solutions: 2 and 3; Then, run the algorithm on b which gives: 2 and 1. Merging them to obtain the solutions for the pair (a, b) is given by the cartesian product of those solutions, which will give you non reachable solutions.
The algorithm has some limitations though: if you track some variables which are memory values, you may face aliasing problems. For example, if you track @32[ESP], the algorithm will track syntactically @32[ESP]. For example:
@32[ESP] = 0x1
ESP = ESP + 0x4
a = @32[ESP]
In this example, if you backtrack a, the algorithm will simply return one solution: 0x1 (which may be wrong). More on this later.
A last example: What are the possible values of x here?

Shell example
Answer:
- solution 1: x = 0x2
- solution 2: x = 0x1
And there is no other solution.
Showcase 1: tracking x86_64 register arguments
In Windows calling convention, the first four arguments are passed from the caller to the callee in the registers RCX, RDX, R8, R9. Let’s take a binary of the Equation Group as example: ntevtx64.sys. The strings manipulated by the program are obfuscated. When the program uses one of the strings, it first calls a function that takes three arguments:
- RCX: a pointer which will store the decrypted string
- RDX: a pointer to the encrypted string
- R8: the length of the string
Here is a trivial call:

Simple call to a string decyphering routine
The function at address 0x6918 is the function responsible for the decryption of the string. In this example, it’s trivial to recover all arguments. Here is the corresponding IR for instance:

Simple call to a string decyphering routine (IR)
In this case:
- RCX: ptr in stack
- RDX: 0x6185+0x2F7BB
- R8: 0xAC
We may use those arguments in the future to emulate the function in order to decipher the string for this reference. I concede this one can be done by hand. But how many references does the deciphering function have? 82. This may be done by hand as well, but it starts to be a bit painful.
Here is an example:

Call to a string decyphering routine
Can you track back R8 and RDX from the CALL ? In this one, the trick is that R8 depends on R12, but its value is always set to zero (set at 0x3137).
How can we automate the argument analysis for each reference? DepGraph of course! Here, both R8 and RDX are tracked in the same analysis to avoid independent solutions for each of them. If some nested loops are involved in their generation, we will be aware of it (and make a manual analysis for example).
To test it, you can use the example in miasm/example/symbol_exec/depgraph.py
$ python2 depgraph.py -h
usage: Dependency grapher [-h] [-m ARCHITECTURE] [-i] [--unfollow-mem]
[--unfollow-call] [--do-not-simplify]
[--rename-args] [--json]
filename func_addr target_addr element [element ...]
positional arguments:
filename Binary to analyse
func_addr Function address
target_addr Address to start
element Elements to track
...
Let’s run the example on the previous function:
$ python2 miasm/example/symbol_exec/depgraph.py ntevtx64.sys 0x311C 0x3180 R8 RDX
Solution 0: R8=0x14, RDX=0x35338 -> sol_0.dot
By the way, this example is also available in the form of an IDA plugin located in miasm/example/ida/depgraph.py
To automate this for every call to the string decryption routine in the binary, we can extract every reference to it (at address 0x6918) using an IDA script:
addr_dec_str = 0x16918
for ref in idautils.XrefsTo(addr_dec_str):
ref_addr = ref.frm
func = idaapi.get_func(ref_addr)
print hex(func.startEA), hex(ref_addr)
Python>
0x1311cL 0x13180L
0x13b48L 0x13c2eL
0x13b48L 0x13cd3L
0x13b48L 0x13d69L
0x13b48L 0x13e26L
...
Note: The binary we are currently working on has an image base of 0, but IDA rebases the binary at 0x10000 by default. This will explain the 0x10000 between IDA addresses, and those manipulated in Miasm (which keeps the default image base).
Now, we can run the previous tool in command line with these values.
python2 ~/projet/miasm/example/symbol_exec/depgraph.py ntevtx64.sys 0x311c 0x3180 R8 RDX
Solution 0: R8=0x14, RDX=0x35338 -> sol_0.dot
python2 ~/projet/miasm/example/symbol_exec/depgraph.py ntevtx64.sys 0x3b48 0x3c2e R8 RDX
Solution 0: R8=0x11, RDX=0x355D8 -> sol_0.dot
python2 ~/projet/miasm/example/symbol_exec/depgraph.py ntevtx64.sys 0x3b48 0x3cd3 R8 RDX
Solution 0: R8=0x11, RDX=0x355D8 -> sol_0.dot
...
For the moment we cannot run most Miasm scripts directly in IDA because IDA uses a bundled 32 bit python, and the host now uses python 64bit in most cases (except for pure python Miasm script, which depgraph belongs to)
Anyway, my preferred way to use Miasm in IDA is to run a rypc server in IDA, and to use it in an external Python. Server code (to run in IDA):
import rpyc
from rpyc.utils.server import OneShotServer
from rpyc.core import SlaveService
import threading
def serve_threaded():
print 'Running server'
def run_thread():
t = OneShotServer(SlaveService, hostname="localhost",
port=4455, reuse_addr=True, ipv6=False,
authenticator=None,
auto_register=False)
t.logger.quiet = False
t.start()
run_thread()
try:
serve_threaded()
except e:
print "ERROR", e
You can install rpyc in IDA by copying its file in ida/python/rpyc. This is possible because rpyc is in pure python.
You can now use IDA in a host script, for example depgraph_find_args.py:
- retrieve references to the deciphering function
- retrieve the parent function
- disassemble and get the IR of the function (cache it)
- find the IR block corresponding to the call reference
- run the depgraph
First run the rpyc server in IDA, then run this script on the host. Result:
Solution for '0x13180L': 0x35338 0x14
Solution for '0x13c2eL': 0x355D8 0x11
Solution for '0x13cd3L': 0x355D8 0x11
Solution for '0x13d69L': 0x355D8 0x11
Solution for '0x13e26L': 0x355F0 0x1C
Solution for '0x13e83L': 0x355F0 0x1C
Solution for '0x13f3bL': 0x35630 0x1C
Solution for '0x13f98L': 0x35630 0x1C
Solution for '0x1404cL': 0x35610 0x1C
Solution for '0x140adL': 0x35610 0x1C
Solution for '0x14158L': 0x350C0 0x44
Solution for '0x14e8eL': 0x35338 0x14
Solution for '0x1601cL': 0x359E0 0xE
...
In this sample, every call has been resolved by the script.
Bonus: we can use those solutions to run a Miasm sandbox and get the deciphered strings. Here is the additional code:
from miasm2.analysis.sandbox import Sandbox_Win_x86_64
from miasm2.os_dep.win_api_x86_32 import winobjs
...
parser = Sandbox_Win_x86_64.parser(description="PE sandboxer")
parser.add_argument("filename", help="PE Filename")
options = parser.parse_args()
options.jitter="gcc"
sb = Sandbox_Win_x86_64(options.filename, options, globals())
alloc_addr = winobjs.heap.alloc(sb.jitter, 0x1000)
def run_func_args(dec_addr, addr, l):
sb.jitter.vm.set_exception(0)
sb.jitter.vm.set_mem(alloc_addr, "\x00"*0x1000)
# Arguments
sb.jitter.cpu.R8 = l
sb.jitter.cpu.RDX = addr
sb.jitter.cpu.RCX = alloc_addr
sb.jitter.push_uint64_t(0x1337beef)
# Run
sb.run(dec_addr)
str_dec = sb.jitter.vm.get_mem(alloc_addr, l)
out = str_dec
# Quick and dirty unicode detection
if len(str_dec) > 1 and str_dec[1] == "\x00":
s = sb.jitter.get_str_unic(alloc_addr)
else:
s = sb.jitter.get_str_ansi(alloc_addr)
print repr(s)
return str_dec
And the output:
Solution for '0x13180L': 0x35338 0x14
'NDISWANIP'
Solution for '0x13c2eL': 0x355D8 0x11
'\r\n Adapter: '
Solution for '0x13cd3L': 0x355D8 0x11
'\r\n Adapter: '
Solution for '0x13d69L': 0x355D8 0x11
'\r\n Adapter: '
Solution for '0x13e26L': 0x355F0 0x1C
' IP: %d.%d.%d.%d\r\n'
Solution for '0x13e83L': 0x355F0 0x1C
' IP: %d.%d.%d.%d\r\n'
Solution for '0x13f3bL': 0x35630 0x1C
' Mask: %d.%d.%d.%d\r\n'
Solution for '0x13f98L': 0x35630 0x1C
' Mask: %d.%d.%d.%d\r\n'
Solution for '0x1404cL': 0x35610 0x1C
' Gateway: %d.%d.%d.%d\r\n'
Solution for '0x140adL': 0x35610 0x1C
' Gateway: %d.%d.%d.%d\r\n'
Solution for '0x14158L': 0x350C0 0x44
' MAC: %.2x-%.2x-%.2x-%.2x-%.2x-%.2x Sent: %.10d Recv: %.10d\r\n'
Solution for '0x14e8eL': 0x35338 0x14
'NDISWANIP'
Solution for '0x1601cL': 0x359E0 0xE
'\\??\\'
Solution for '0x16191L': 0x35940 0xAC
'\\Registry\\Machine\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\Adapters'
Solution for '0x16296L': 0x35338 0x14
'NDISWANIP'
Solution for '0x16648L': 0x359E0 0xE
'\\??\\'
Solution for '0x16799L': 0x35940 0xAC
'\\Registry\\Machine\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\Adapters'
Solution for '0x168dcL': 0x35338 0x14
'NDISWANIP'
...
You can also add some code to comment the IDA database with the freshly deciphered strings:
...
conn.modules.idc.MakeComm(ref.frm, "DEC: %r" % str_dec)
The rpyc server: ida_rpyc.py (to run in IDA)
The final script is here: depgraph_find_args_run.py (to run out of IDA)
Showcase 2: tracking arguments on the stack
The binary ntevt.sys should be the same driver as ntevtx64.sys, but in 32 bits. The deciphering function is also present, here is a call example:

Native x86
As I said previously, the DepGraph algorithm tracks one or more expressions. The problem is that when you translate native code into IR, the memory access expression remains the same, but the stack pointer evolves. Example of native code:

Call in native x86
And its corresponding IR:

Call in IR
Note the multiple writes to @32[ESP-4]. If you want to track memory values, you first have to resolve their pointers. Once each memory pointer is resolved (which is not a simple task), you might start the memory analysis. In the present case, ESP must be replaced by something so that the DepGraph algorithm is aware that each stack argument is different.
The simple solution: we will express ESP in terms of its value at the entry of the function ESP_init and its current offset to this value. We can use IDA as an oracle here, which provides this offset by calling GetSpd.
To do so, we will make a IRA subclass which will apply this modification during the native to IR translation:
class ira_fix_stk(machine.ira):
def gen_stk_update(self, instr):
"""
Get ESP offset to ESP_init using IDA as euristic
"""
stk_off = ExprInt(conn.modules.idc.GetSpd(instr.offset + 0x10000), self.sp.size)
return machine.mn.regs.regs_init[self.sp] + stk_off
def fix_assignblk_stack(self, assignblk, stk_high):
"""
Replace ESP acceses with it's relative value from ESP_init
"""
for dst, src in assignblk.items():
del(assignblk[dst])
stk_info = {self.sp:stk_high}
src = expr_simp(src.replace_expr(stk_info))
if dst != self.sp:
dst = expr_simp(dst.replace_expr(stk_info))
assignblk[dst] = src
def add_instr_to_irblock(self, block, instr, irb_cur, ir_blocks_all, gen_pc_updt):
"""
Quick and dirty ESP fix
"""
irb_cur = self.pre_add_instr(block, instr, irb_cur, ir_blocks_all, gen_pc_updt)
if irb_cur is None:
return None
assignblk, ir_blocs_extra = self.instr2ir(instr)
if gen_pc_updt is not False:
self.gen_pc_update(irb_cur, instr)
stk_high = self.gen_stk_update(instr)
self.fix_assignblk_stack(assignblk, stk_high)
irb_cur.irs.append(assignblk)
irb_cur.lines.append(instr)
if ir_blocs_extra:
for b in ir_blocs_extra:
b.lines = [instr] * len(b.irs)
ir_blocks_all += ir_blocs_extra
irb_cur = None
return irb_cur
This code is really a quick&dirty hack: it doesn’t even fix every assign block. But it works for now. Result:

Call in IR, stack fixed
How to run the DepGraph now?
- get the call line
- get the ESP value, relative to its initial value plus offset given by IDA
- depgraph the second and third arguments, retrieved with the previous base
In the current example, the current ESP is ESP_init + 0xFFFFFFC8, so we will run a dependency graph on (@32[ESP_init+0xFFFFFFCC], @32[ESP_init+0xFFFFFFD0]). This will give us a unique solution: (0x26310, 0x14).
If you don’t forget to fix the run_func_args to push arguments on the stack instead of using registers, and force the use of a 32bit sandbox, all the strings are resolved, and you should have:
Solution for '0x1171fL': 0x26310 0x14
'NDISWANIP'
Solution for '0x11f24L': 0x26580 0x11
'\r\n Adapter: '
Solution for '0x11fbeL': 0x26580 0x11
'\r\n Adapter: '
Solution for '0x12045L': 0x26580 0x11
'\r\n Adapter: '
Solution for '0x120f5L': 0x26594 0x1C
' IP: %d.%d.%d.%d\r\n'
Solution for '0x1214cL': 0x26594 0x1C
' IP: %d.%d.%d.%d\r\n'
Solution for '0x121e7L': 0x265CC 0x1C
' Mask: %d.%d.%d.%d\r\n'
Solution for '0x1223eL': 0x265CC 0x1C
' Mask: %d.%d.%d.%d\r\n'
Solution for '0x122d9L': 0x265B0 0x1C
' Gateway: %d.%d.%d.%d\r\n'
Solution for '0x12330L': 0x265B0 0x1C
' Gateway: %d.%d.%d.%d\r\n'
Solution for '0x123beL': 0x26098 0x44
' MAC: %.2x-%.2x-%.2x-%.2x-%.2x-%.2x Sent: %.10d Recv: %.10d\r\n'
Solution for '0x12d4eL': 0x26310 0x14
'NDISWANIP'
Solution for '0x13a55L': 0x267CC 0xE
'\\??\\'
Solution for '0x13b9fL': 0x268B8 0xAC
'\\Registry\\Machine\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\Adapters'
Solution for '0x13c97L': 0x26310 0x14
'NDISWANIP'
Solution for '0x13f5cL': 0x267CC 0xE
'\\??\\'
Solution for '0x14088L': 0x268B8 0xAC
'\\Registry\\Machine\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\Adapters'
Solution for '0x141b9L': 0x26310 0x14
'NDISWANIP'
...
Looks familiar? These are the same strings as the 64 bit driver! Did I mention that with the help of elfesteem, we can add a section and patch the binary so that the strings appear in clear, with their references used in the code ?
Here is a demo using the Miasm’s depgraph IDA script. In this example, we will track the first argument of the dec_str function call. As the arguments in this example are passed through the stack, we need to follow memory variables, and use the un-alias oracle from IDA (we hit shift-N to switch to the next solution):
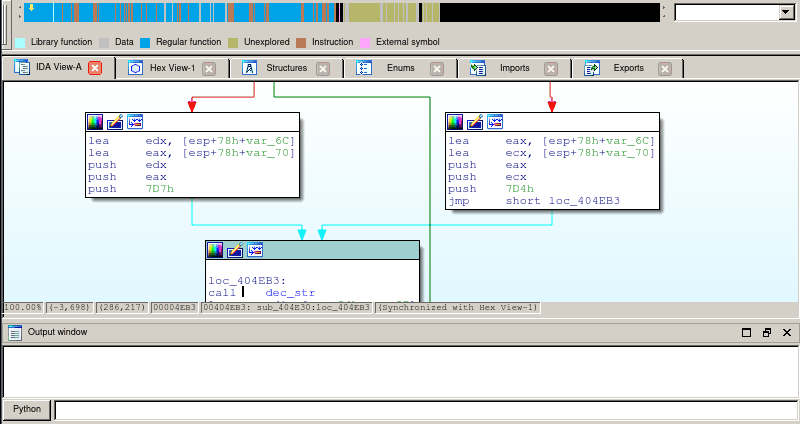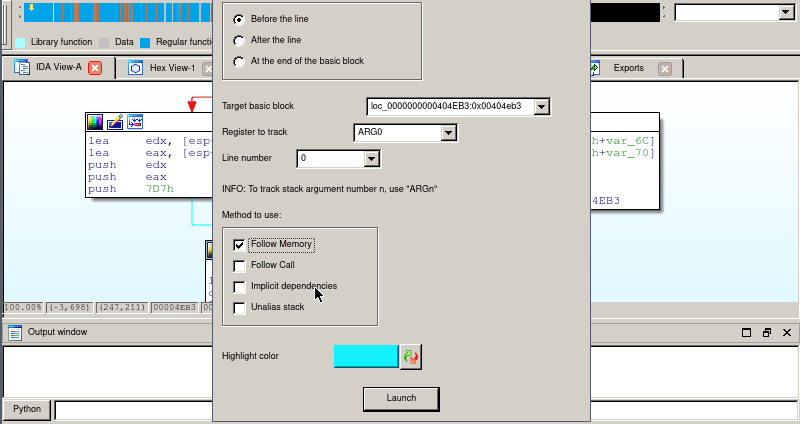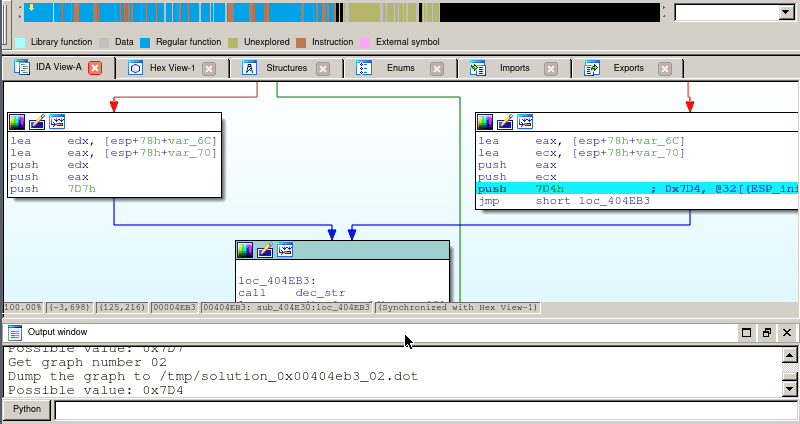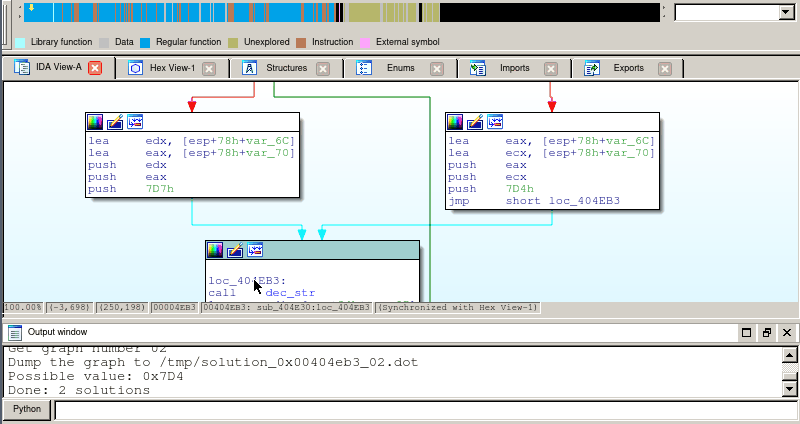
Depgraph IDA plugin
Conclusion
In this post, we used the dependency graph algorithm to retrieve the ciphered strings in an Equation Group malware. The algorithm works well in classical cases (stack, arguments, …). An important point is that even in complex cases (with nested loops, …) we will still have the graph of dependencies, which can be used for range analysis, or any other algorithm. When asked for a final value, the algorithm is able to tell if the result can be trusted (regarding loop dependencies).
Another example? The dependency graph on the flags used to determine the end of a loop will directly give you the index of the loop, its update and its initialization.